Why we updated our insights for the Agentic Web
// Context
The Shift: From Browsers to Retrievers
For the last decade, SEO was about keywords. You optimized a page so a human would click it, read it, and stay on the site. Today, we are optimizing for AI Agents.
LLMs (Large Language Models) like ChatGPT, Claude, and Gemini do not "browse" like humans. They retrieve, synthesize, and cite. When an AI crawls a website, it doesn't look for pretty design; it looks for Semantic Structure.
To align with this reality, we just executed a complete restructuring of the WITTIGONIA digital footprint.
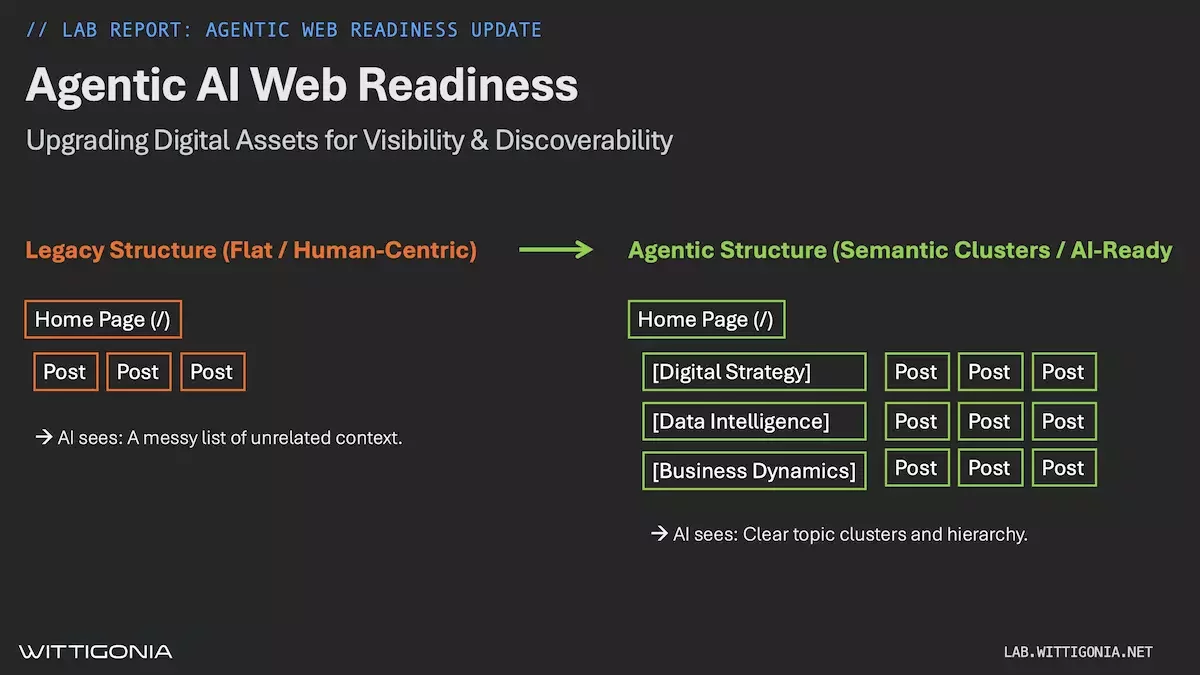
The Strategy: Semantic Silos
We moved from a flat URL structure (domain.com/post-name) to a strict semantic hierarchy:
Old Way: Flat, ambiguous. An AI sees a list of 100 posts and has to guess which ones are related.
New Way (The Agentic Protocol):
/insights/digital-strategy/(Context: Architecture)/insights/data-intelligence/(Context: Truth)/insights/business-dynamics/(Context: Systems)
By grouping content into these "Silos," we force the crawler to understand the relationship between topics before it even reads a single word.
// Protocol
The Protocol: llms.txt
Alongside the URL migration, we deployed our llms.txt protocol. This is a markdown file specifically designed for AI scrapers. It strips away the HTML, CSS, and JavaScript bloat and offers a clean "Knowledge Graph" of our core capabilities. Note: llms.txt is still an early approach. And at this stage the impact is not entirely clear. It may very well be that crawlers, bots and AI agents pick up the information or simply ignore it.
The "Hidden" Gotcha (Developer Note)
During deployment, we encountered a critical infrastructure nuance that many businesses miss. Modern CMS setups often virtualize the robots.txt file. However, strict crawlers (Lighthouse, Googlebot) expect a physical file at the absolute server root.
The Trap: We had files in
/html/(Generic Root) instead of/wittigonia.net/(Application Root).The Result: Browsers saw the file, but bots saw a 404.
The Fix: We bypassed the CMS and hard-coded the
llms.txtandrobots.txtinto the physical server directory.
// Conclusion
The Takeaway
Digital Transformation isn't just about buying software. It is about Data Architecture. If your business logic isn't structured in a way that an AI can easily retrieve, you are invisible to the next generation of search.
Another step close to AI and Agent Readiness. We will check later when the crawlers revisited the site and see if they can make sense out of the changes and new structure and content.
